KNN is the simplest classification algorithm under supervised machine learning. It stands for K Nearest Neighbors. I have listed down 7 interview questions and answers regarding KNN algorithm in supervised machine learning. I have given only brief answers to the questions. If you want to dive deep into the mentioned KNN interview questions, you can google around to find out detailed answers.
1. What is “K” in KNN algorithm?
2. How do we decide the value of "K" in KNN algorithm?
3. Why is the odd value of “K” preferable in KNN algorithm?
4. What is the difference between Euclidean Distance and Manhattan distance? What is the formula of Euclidean distance and Manhattan distance?
5. Why is KNN algorithm called Lazy Learner?
6. Why should we not use KNN algorithm for large datasets?
7. What are the advantages and disadvantages of KNN algorithm?
Lets try to explore the answers to the above mentioned KNN algorithm interview questions.
1. What is “K” in KNN algorithm?
K = Number of nearest neighbors you want to select to predict the class of a given item
2. How do we decide the value of "K" in KNN algorithm?
If K is small, then results might not be reliable because noise will have a higher influence on the result. If K is large, then there will be a lot of processing which may adversely impact the performance of the algorithm. So, following is must be considered while choosing the value of K:
a. K should be the square root of n (number of data points in training dataset)
b. K should be odd so that there are no ties. If square root is even, then add or subtract 1 to it.
More details...
3. Why is the odd value of “K” preferable in KNN algorithm?
K should be odd so that there are no ties in the voting. If square root of number of data points is even, then add or subtract 1 to it to make it odd.
4. What is the difference between Euclidean Distance and Manhattan distance? What is the formula of Euclidean distance and Manhattan distance?
Both are used to find out the distance between two points.

Euclidean Distance and Manhattan Distance Formula

(Image taken from stackexchange)
5. Why is KNN algorithm called Lazy Learner?
When it gets the training data, it does not learn and make a model, it just stores the data. It does not derive any discriminative function from the training data. It uses the training data when it actually needs to do some prediction. So, KNN does not immediately learn a model, but delays the learning, that is why it is called lazy learner.
6. Why should we not use KNN algorithm for large datasets?
KNN works well with smaller dataset because it is a lazy learner. It needs to store all the data and then makes decision only at run time. It needs to calculate the distance of a given point with all other points. So if dataset is large, there will be a lot of processing which may adversely impact the performance of the algorithm.
KNN is also very sensitive to noise in the dataset. If the dataset is large, there are chances of noise in the dataset which adversely affect the performance of KNN algorithm.
7. What are the advantages and disadvantages of KNN algorithm?
Answer
1. What is “K” in KNN algorithm?
2. How do we decide the value of "K" in KNN algorithm?
3. Why is the odd value of “K” preferable in KNN algorithm?
4. What is the difference between Euclidean Distance and Manhattan distance? What is the formula of Euclidean distance and Manhattan distance?
5. Why is KNN algorithm called Lazy Learner?
6. Why should we not use KNN algorithm for large datasets?
7. What are the advantages and disadvantages of KNN algorithm?
Lets try to explore the answers to the above mentioned KNN algorithm interview questions.
1. What is “K” in KNN algorithm?
K = Number of nearest neighbors you want to select to predict the class of a given item
2. How do we decide the value of "K" in KNN algorithm?
If K is small, then results might not be reliable because noise will have a higher influence on the result. If K is large, then there will be a lot of processing which may adversely impact the performance of the algorithm. So, following is must be considered while choosing the value of K:
a. K should be the square root of n (number of data points in training dataset)
b. K should be odd so that there are no ties. If square root is even, then add or subtract 1 to it.
More details...
3. Why is the odd value of “K” preferable in KNN algorithm?
K should be odd so that there are no ties in the voting. If square root of number of data points is even, then add or subtract 1 to it to make it odd.
4. What is the difference between Euclidean Distance and Manhattan distance? What is the formula of Euclidean distance and Manhattan distance?
Both are used to find out the distance between two points.
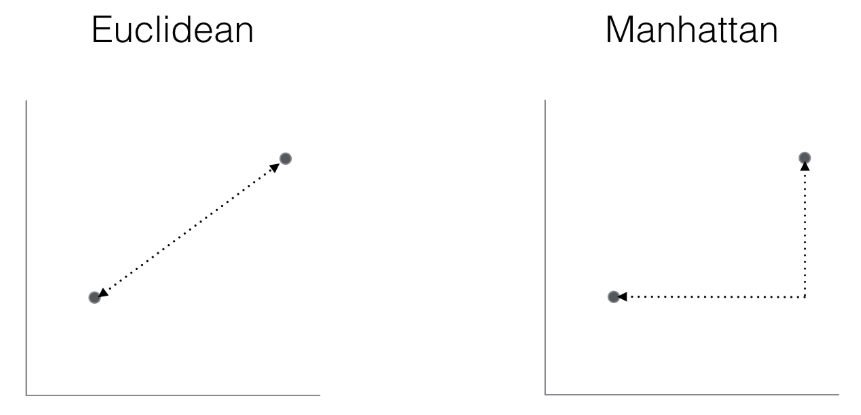
Euclidean Distance and Manhattan Distance Formula

(Image taken from stackexchange)
5. Why is KNN algorithm called Lazy Learner?
When it gets the training data, it does not learn and make a model, it just stores the data. It does not derive any discriminative function from the training data. It uses the training data when it actually needs to do some prediction. So, KNN does not immediately learn a model, but delays the learning, that is why it is called lazy learner.
6. Why should we not use KNN algorithm for large datasets?
KNN works well with smaller dataset because it is a lazy learner. It needs to store all the data and then makes decision only at run time. It needs to calculate the distance of a given point with all other points. So if dataset is large, there will be a lot of processing which may adversely impact the performance of the algorithm.
KNN is also very sensitive to noise in the dataset. If the dataset is large, there are chances of noise in the dataset which adversely affect the performance of KNN algorithm.
7. What are the advantages and disadvantages of KNN algorithm?
Answer
Good One
ReplyDelete