There are mainly four activation functions (step, sigmoid, tanh and relu) used in neural networks in deep learning. These are also called squashing functions as these functions squash the output under certain range. We will also see various advantages and disadvantages of different activation functions.
Importance of Activation Functions in Neural Networks
These activation functions help in achieving non-linearity in deep learning models. If we don't use these non-linear activation functions, neural network would not be able to solve the complex real life problems like image, video, audio, voice and text processing, natural language processing etc. because our neural network would still be linear and linear models cannot solve real life complex problems.
Although linear models are simple but are computationally weak and not able to handle complex problems. So, if you don't use activation functions, no matter how many hidden layers you use in your neural network, it will still be linear an inefficient.
Lets discuss these activation functions in detail.
1. Step (Threshold) Activation Function
It either outputs 0 or 1 (Yes or No). It is non-linear in nature.
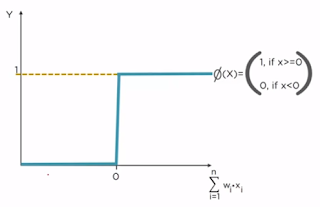
There is a sudden change in the decision (from 0 to 1) when input value crosses the threshold value. For most real-world applications, we would expect a smoother decision function which gradually changes from 0 to 1.
Lets take a real life example of this step function. Consider a movie. If the critics rating is below or equal to 0.5, step function will output 0 (don't watch this movie). If it is above 0.50, step function will output 1 (go and watch this movie).
What would be the decision for a movie with critics rating = 0.51? Yes!
What would be the decision for a movie with critics rating = 0.49? No!
It appears harsh that we would watch a movie with a rating of 0.51 but not the one with a rating of 0.49 and this is where sigmoid function comes into the picture.
As step function either outputs 0 or 1 (Yes or No), it is a non-differentiable activation function and therefore its derivative will always be zero.
2. Sigmoid Activation Function
It is also called Logistic activation function. Its output ranges from 0 to 1. It has "S" shaped curve. Sigmoid function is much smoother than the step function which seems logical and obvious in real life example as discussed above.

Advantages of Sigmoid Activation Function
1. Sigmoid is a non-linear activation function.
2. Instead of just outputting 0 and 1, it can output any value between 0 and 1 like 0.62, 0.85, 0.98 etc. So, instead of just Yes or No, it outputs a probability value. So, the output of sigmoid function is is smooth, continuous and differentiable.
3. As the range of output remains between 0 and 1, it cannot blow up the activations unlike ReLu activation function.
Disadvantages of Sigmoid Activation Function
1. Vanishing and exploding gradients problem
2. Computing the exponential may be expensive sometimes
3. Tanh (Hyperbolic Tangent) Activation Function
It is similar to Sigmoid Activation Function, the only difference is that it outputs the values in the range of -1 to 1 instead of 0 and 1 (like sigmoid function). So, we can say that tanh function is zero centered (unlike sigmoid function) as its values range from -1 to 1 instead of 0 to 1.

Advantages and Disadvantages of Tanh activation function are same as that of sigmoid activation function.
4. ReLu (Rectified Linear Unit)
ReLU outperforms both sigmoid and tanh functions and is computationally more efficient compared to both. Given an input value, the ReLu will generate 0, if the input is less than 0, otherwise the output will be the same as the input.
Mathematically, relu(z) = max(0, z)
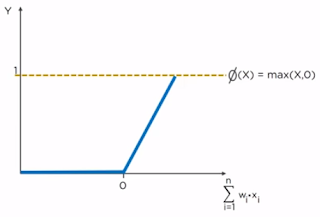
Advantages of ReLu Activation Function
1. It does not require exponent calculation as it is done in sigmoid and tanh activation functions.
2. It does not encounter vanishing gradient problem.
Disadvantages of ReLu
1. Dying ReLu: The dying ReLu is a phenomenon where a neuron in the network is permanently dead due to inability to fire in the forward pass. This problem occurs when the activation value generated by a neuron is zero while in forward pass, which resulting that its weights will get zero gradient. As a result, when we do back-propagation, the weights of that neuron will never be updated and that particular neuron will never be activated.
Leaky ReLU with a small positive gradient for negative inputs (y=0.01x when x < 0 say) is one attempt to address this issue and give a chance to recover. One more attempt is Max ReLU. I will add more details about these later on or may write a separate article.
2. Unbounded output range: Unbounded output values generated by ReLu could make the computation within the RNN likely to blow up to infinity without reasonable weights. As a result, the learning can be remarkably unstable because a slight shift in the weights in the wrong direction during back-propagation can blow up the activations during the forward pass.
Which one to use: We should use ReLu instead of sigmoid and tanh because of its high efficiency. ReLu should be used for hidden layers and softmax should be used for output layers for classification and regression problems.
Importance of Activation Functions in Neural Networks
These activation functions help in achieving non-linearity in deep learning models. If we don't use these non-linear activation functions, neural network would not be able to solve the complex real life problems like image, video, audio, voice and text processing, natural language processing etc. because our neural network would still be linear and linear models cannot solve real life complex problems.
Although linear models are simple but are computationally weak and not able to handle complex problems. So, if you don't use activation functions, no matter how many hidden layers you use in your neural network, it will still be linear an inefficient.
Lets discuss these activation functions in detail.
1. Step (Threshold) Activation Function
It either outputs 0 or 1 (Yes or No). It is non-linear in nature.
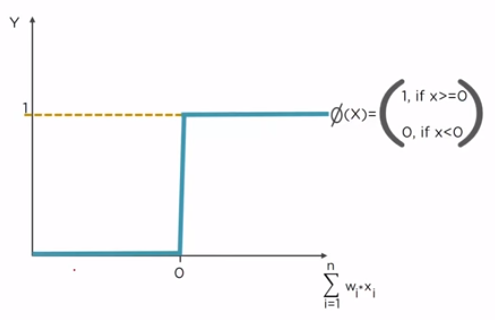
There is a sudden change in the decision (from 0 to 1) when input value crosses the threshold value. For most real-world applications, we would expect a smoother decision function which gradually changes from 0 to 1.
Lets take a real life example of this step function. Consider a movie. If the critics rating is below or equal to 0.5, step function will output 0 (don't watch this movie). If it is above 0.50, step function will output 1 (go and watch this movie).
What would be the decision for a movie with critics rating = 0.51? Yes!
What would be the decision for a movie with critics rating = 0.49? No!
It appears harsh that we would watch a movie with a rating of 0.51 but not the one with a rating of 0.49 and this is where sigmoid function comes into the picture.
As step function either outputs 0 or 1 (Yes or No), it is a non-differentiable activation function and therefore its derivative will always be zero.
2. Sigmoid Activation Function
It is also called Logistic activation function. Its output ranges from 0 to 1. It has "S" shaped curve. Sigmoid function is much smoother than the step function which seems logical and obvious in real life example as discussed above.
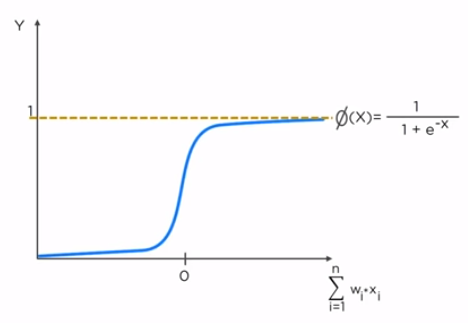
Advantages of Sigmoid Activation Function
1. Sigmoid is a non-linear activation function.
2. Instead of just outputting 0 and 1, it can output any value between 0 and 1 like 0.62, 0.85, 0.98 etc. So, instead of just Yes or No, it outputs a probability value. So, the output of sigmoid function is is smooth, continuous and differentiable.
3. As the range of output remains between 0 and 1, it cannot blow up the activations unlike ReLu activation function.
Disadvantages of Sigmoid Activation Function
1. Vanishing and exploding gradients problem
2. Computing the exponential may be expensive sometimes
3. Tanh (Hyperbolic Tangent) Activation Function
It is similar to Sigmoid Activation Function, the only difference is that it outputs the values in the range of -1 to 1 instead of 0 and 1 (like sigmoid function). So, we can say that tanh function is zero centered (unlike sigmoid function) as its values range from -1 to 1 instead of 0 to 1.

Advantages and Disadvantages of Tanh activation function are same as that of sigmoid activation function.
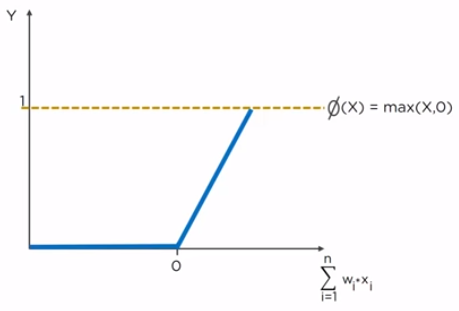
4. ReLu (Rectified Linear Unit)
ReLU outperforms both sigmoid and tanh functions and is computationally more efficient compared to both. Given an input value, the ReLu will generate 0, if the input is less than 0, otherwise the output will be the same as the input.
Mathematically, relu(z) = max(0, z)
Advantages of ReLu Activation Function
1. It does not require exponent calculation as it is done in sigmoid and tanh activation functions.
2. It does not encounter vanishing gradient problem.
Disadvantages of ReLu
1. Dying ReLu: The dying ReLu is a phenomenon where a neuron in the network is permanently dead due to inability to fire in the forward pass. This problem occurs when the activation value generated by a neuron is zero while in forward pass, which resulting that its weights will get zero gradient. As a result, when we do back-propagation, the weights of that neuron will never be updated and that particular neuron will never be activated.
Leaky ReLU with a small positive gradient for negative inputs (y=0.01x when x < 0 say) is one attempt to address this issue and give a chance to recover. One more attempt is Max ReLU. I will add more details about these later on or may write a separate article.
2. Unbounded output range: Unbounded output values generated by ReLu could make the computation within the RNN likely to blow up to infinity without reasonable weights. As a result, the learning can be remarkably unstable because a slight shift in the weights in the wrong direction during back-propagation can blow up the activations during the forward pass.
Which one to use: We should use ReLu instead of sigmoid and tanh because of its high efficiency. ReLu should be used for hidden layers and softmax should be used for output layers for classification and regression problems.
No comments:
Post a Comment