I have created a list of basic Machine Learning Interview Questions and Answers. These Machine Learning Interview Questions are common, simple and straight-forward.
These questions are categorized into 8 groups:
1. Basic Introduction
2. Data Exploration and Visualization
3. Data Preprocessing and Wrangling
4. Dimensionality Reduction
5. Algorithms
6. Accuracy Measurement
7. Python
8. Practical Implementations
These Machine Learning Interview Questions cover following basic concepts of Machine Learning:
1. General introduction to Machine Learning
2. Data Analysis, Exploration, Visualization and Wrangling techniques
3. Dimensionality Reduction techniques like PCA (Principal Component Analysis), SVD (Singular Vector Decomposition), LDA (Linear Discriminant Analysis), MDS (Mulit-dimension Scaling), t-SNE (t-Distributed Stochastic Neighbor Embedding) and ICA (Independent Component Analysis)
4. Supervised and Unsupervised Machine Learning algorithms like K-Nearest Neighbors (KNN), Naive Bayes, Decision Trees, Random Forest, Support Vector Machines (SVM), Linear Regression, Logistic Regression, K-Means Clustering, Time Series Analysis, Sentiment Analysis etc
5. Bias and Variance, Overfitting and Underfitting, Cross-validation
6. Regularization, Ridge, Lasso and Elastic Net Regression
7. Bagging and Boosting techniques like Random Forest, AdaBoost, Gradient Boosting Machine (GBM) and XGBoost.
8. Basic data structures and libraries of Python used in Machine Learning
I will keep on adding more questions to this list in future.
Note: For Deep Learning Interview Questions, refer this link.
Basic Introduction (7 Questions)
1. What is Machine Learning? What are its various applications? Why is Machine Learning gaining so much attraction now-a-days?
2. What is the difference between Artificial Intelligence, Machine Learning and Deep Learning?
3. What are various types of Machine Learning? What is Supervised Learning, Unsupervised Learning, Semi-supervised Learning and Reinforcement Learning? Give some examples of these types of Machine Learning.
4. Explain Deep Learning and Neural Networks.
5. What is the difference between Data Mining and Machine learning?
6. What is the difference between Inductive and Deductive Machine Learning?
7. What are the various steps involved in a Machine Learning Process?
Data Exploration and Visualization (4 Questions)
1. What is Hypothesis Generation? What is the difference between Null Hypothesis (Ho) and Alternate Hypothesis (Ha)? Answer
2. What is Univariate, Bivariate and Multivariate Data Exploration? Answer
3. Explain various plots and grids available for data exploration in seaborn and matplotlib libraries?
Joint Plot, Distribution Plot, Box Plot, Bar Plot, Regression Plot, Strip Plot, Heatmap, Violin Plot, Pair Plot and Grid, Facet Grid
4. How will you visualize missing values, outliers, skewed data and correlations using plots and grids? Answer
Data Preprocessing and Wrangling (19 Questions)
1. What is the difference between Data Processing, Data Preprocessing and Data Wrangling?
2. What is Data Wrangling? What are the various steps involved in Data Wrangling? Answer
3. What is the difference between Labeled and Unlabeled data?
4. What do you mean by Features and Labels in the dataset?
5. What are the Independent / Explanatory and Dependent variables?
6. What is the difference between Continuous and Categorical / Discrete variables?
7. What do you mean by Noise in the dataset? How to remove it?
8. What are Skewed Variables and Outliers in the dataset? What are the various ways to visualize and remove these? What do you mean by log transformation of skewed variables? Answer 1, Answer 2, Answer 3, Answer 4, Answer 5
9. What are the various ways to handle missing and invalid data in a dataset? What is Imputer? Answer 1, Answer 2, Answer 3, Answer 4, Answer 5
10. What is the difference between Mean, Median and Mode? How are these terms used to impute missing values in numeric variables? Answer
11. How will you calculate Mean, Variance and Standard Deviation of a feature / variable in a given dataset? What is the formula?
12. How will you convert categorical variables into dummies? Answer 1, Answer 2
13. What is Binning Technique? What is the difference between Fixed Width Binning and Adaptive Binning? Answer
14. What is Feature Scaling? What is the difference between Normalization and Standardization? Answer 1, Answer 2, Answer 3, Answer 4
15. Which Machine Learning Algorithms require Feature Scaling (Standardization and Normalization) and which not? Answer
16. What do you mean by Imbalanced Datasheet? How will you handle it?
17. What is the difference between "Training" dataset and "Test" dataset? What are the common ratios we generally maintain between them?
18. What is the difference between Validation set and Test set?
19. What do you understand by Fourier Transform? How is it used in Machine Learning?
Dimensionality Reduction (9 Questions)
1. What is Multicollinearity? What is the difference between Covariance and Correlation? How are these terms related with each other? Answer 1, Answer 2
2. Feature Selection and Feature Extraction
4. Principal Component Analysis
6. Linear Discriminant Analysis
Algorithms (27 Questions)
1. Types of ML Algorithms
11. Decision Tree
14. Bias and Variance
20. GBM (Gradient Boosting Machine)
22. XGBoost
24. K-Means Clustering
26. Time Series Analysis
1. Name some metrics which we use to measure the accuracy of the classification and regression algorithms.
Hint:
Classification metrics: Confusion Matrix, Classification Report, Accuracy Score etc.
Regression metrics: MAE, MSE, RMSE Answer
2. What is Confusion Matrix? What do you mean by True Positive, True Negative, False Positive and False Negative in Confusion Matrix?
3. How do we manually calculate Accuracy Score from Confusion Matrix?
4. What is Sensitivity (True Positive Rate) and Specificity (True Negative Rate)? How will you calculate it from Confusion Matrix? What is its formula?
5. What is the difference between Precision and Recall? How will you calculate it from Confusion Matrix? What is its formula?
6. What do you mean by ROC (Receiver Operating Characteristic) curve and AUC (Area Under the ROC Curve)? How is this curve used to measure the performance of a classification model?
7. What do you understand by Type I vs Type II error ? What is the difference between them?
8. What is Classification Report? Describe its various attributes like Precision, Recall, F1 Score and Support.
9. What is the difference between F1 Score and Accuracy Score?
10. What do you mean by Loss Function? Name some commonly used Loss Functions. Define Mean Absolute Error, Mean Squared Error, Root Mean Squared Error, Sum of Absolute Error, Sum of Squared Error, R Square Method, Adjusted R Square Method. Answer
Python (16 Questions)
1. What are the commonly used libraries in Python for Machine Learning? Explain pandas, numpy, sklearn, matplotlib, seaborn and scipy libraries.
2. Which data structures in Python are commonly used in Machine Learning? Explain tuple, list and dictionary. Answer
3. What are mutable and immutable objects in Python?
4. What are the magic functions in IPython?
5. What is the purpose of writing "inline" with "%matplotlib" (%matplotlib inline)?
6. What are the basic steps to implement any Machine Learning algorithm in Python?
Implement KNN in Python
Implement SVC in Python
Implement Naive Bayes in Python
Implement Simple Linear Regression in Python
Implement Multiple Linear Regression in Python
Implement Decision Tree for Classification Problem in Python
Implement Decision Tree for Regression Problem in Python
Implement Random Forest for Classification Problem in Python
Implement Random Forest for Regression Problem in Python
Implement Adaboost in Python
Implement XGBoost For Classification Problem in Python
Implement XGBoost For Regression Problem in Python
7. What are the basic steps to implement any Machine Learning algorithm using Cross Validation (cross_val_score) in Python?
Implement KNN using Cross Validation in Python
Implement Naive Bayes using Cross Validation in Python
Implement XGBoost using Cross Validation in Python
8. Feature Scaling in Python
Implement Standardization in Python
Implement Normalization in Python
9. Encoding in Python
Implement LabelEncoder in Python
Implement OneHotEncoder in Python
Implement get_dummies in Python
10. Imputing in Python
Implement Imputer in Python
11. Binning in Python
Implement Binning in Python using Cut Function
12. Dimensionality Reduction in Python
Implement PCA in Python
13. What is the random_state (seed) parameter in train_test_split?
14. What are the various metrics present in sklearn library to measure the accuracy of an algorithm? Describe classification_report, confusion_matrix, accuracy_score, f1_score, r2_score, score, mean_absolute_error, mean_squared_error.
15. Pandas Library
Data Exploration using Pandas Library in Python
Creating Pandas DataFrame using CSV, Excel, Dictionary, List and Tuple
Boolean Indexing: How to filter Pandas Data Frame?
How to find missing values in each row and column using Apply function in Pandas library?
How to calculate Mean and Median of numeric variables using Pandas library?
Sorting datasets based on multiple columns using sort_values
How to view and change datatypes of variables or features in a dataset?
How to print Frequency Table for all categorical variables using value_counts() function?
Frequency Table: How to use pandas value_counts() function to impute missing values?
How to use Pandas Lambda Functions for Data Wrangling?
How to separate numeric and categorical variables in a dataset using Pandas and Numpy Libraries in Python?
16. Scipy Library
How to find mode of a variable using Scipy library to impute missing values?
Practical Implementations (5 Questions)
1. Write a pseudo code for a given algorithm.
2. What are the parameters on which we decide which algorithm to use for a given situation?
3. How will you design a Chess Game, Spam Filter, Recommendation Engine etc.?
4. How can you use Machine Learning Algorithms to increase revenue of a company?
5. How will you design a promotion campaign for a business using Machine Learning?
These questions are categorized into 8 groups:
1. Basic Introduction
2. Data Exploration and Visualization
3. Data Preprocessing and Wrangling
4. Dimensionality Reduction
5. Algorithms
6. Accuracy Measurement
7. Python
8. Practical Implementations
These Machine Learning Interview Questions cover following basic concepts of Machine Learning:
1. General introduction to Machine Learning
2. Data Analysis, Exploration, Visualization and Wrangling techniques
3. Dimensionality Reduction techniques like PCA (Principal Component Analysis), SVD (Singular Vector Decomposition), LDA (Linear Discriminant Analysis), MDS (Mulit-dimension Scaling), t-SNE (t-Distributed Stochastic Neighbor Embedding) and ICA (Independent Component Analysis)
4. Supervised and Unsupervised Machine Learning algorithms like K-Nearest Neighbors (KNN), Naive Bayes, Decision Trees, Random Forest, Support Vector Machines (SVM), Linear Regression, Logistic Regression, K-Means Clustering, Time Series Analysis, Sentiment Analysis etc
5. Bias and Variance, Overfitting and Underfitting, Cross-validation
6. Regularization, Ridge, Lasso and Elastic Net Regression
7. Bagging and Boosting techniques like Random Forest, AdaBoost, Gradient Boosting Machine (GBM) and XGBoost.
8. Basic data structures and libraries of Python used in Machine Learning
I will keep on adding more questions to this list in future.
Note: For Deep Learning Interview Questions, refer this link.
Basic Introduction (7 Questions)
1. What is Machine Learning? What are its various applications? Why is Machine Learning gaining so much attraction now-a-days?
2. What is the difference between Artificial Intelligence, Machine Learning and Deep Learning?
3. What are various types of Machine Learning? What is Supervised Learning, Unsupervised Learning, Semi-supervised Learning and Reinforcement Learning? Give some examples of these types of Machine Learning.
4. Explain Deep Learning and Neural Networks.
5. What is the difference between Data Mining and Machine learning?
6. What is the difference between Inductive and Deductive Machine Learning?
7. What are the various steps involved in a Machine Learning Process?
Data Exploration and Visualization (4 Questions)
1. What is Hypothesis Generation? What is the difference between Null Hypothesis (Ho) and Alternate Hypothesis (Ha)? Answer
2. What is Univariate, Bivariate and Multivariate Data Exploration? Answer
3. Explain various plots and grids available for data exploration in seaborn and matplotlib libraries?
Joint Plot, Distribution Plot, Box Plot, Bar Plot, Regression Plot, Strip Plot, Heatmap, Violin Plot, Pair Plot and Grid, Facet Grid
4. How will you visualize missing values, outliers, skewed data and correlations using plots and grids? Answer
Data Preprocessing and Wrangling (19 Questions)
1. What is the difference between Data Processing, Data Preprocessing and Data Wrangling?
2. What is Data Wrangling? What are the various steps involved in Data Wrangling? Answer
3. What is the difference between Labeled and Unlabeled data?
4. What do you mean by Features and Labels in the dataset?
5. What are the Independent / Explanatory and Dependent variables?
6. What is the difference between Continuous and Categorical / Discrete variables?
7. What do you mean by Noise in the dataset? How to remove it?
8. What are Skewed Variables and Outliers in the dataset? What are the various ways to visualize and remove these? What do you mean by log transformation of skewed variables? Answer 1, Answer 2, Answer 3, Answer 4, Answer 5
9. What are the various ways to handle missing and invalid data in a dataset? What is Imputer? Answer 1, Answer 2, Answer 3, Answer 4, Answer 5
10. What is the difference between Mean, Median and Mode? How are these terms used to impute missing values in numeric variables? Answer
11. How will you calculate Mean, Variance and Standard Deviation of a feature / variable in a given dataset? What is the formula?
12. How will you convert categorical variables into dummies? Answer 1, Answer 2
13. What is Binning Technique? What is the difference between Fixed Width Binning and Adaptive Binning? Answer
14. What is Feature Scaling? What is the difference between Normalization and Standardization? Answer 1, Answer 2, Answer 3, Answer 4
15. Which Machine Learning Algorithms require Feature Scaling (Standardization and Normalization) and which not? Answer
16. What do you mean by Imbalanced Datasheet? How will you handle it?
17. What is the difference between "Training" dataset and "Test" dataset? What are the common ratios we generally maintain between them?
18. What is the difference between Validation set and Test set?
19. What do you understand by Fourier Transform? How is it used in Machine Learning?
Dimensionality Reduction (9 Questions)
1. What is Multicollinearity? What is the difference between Covariance and Correlation? How are these terms related with each other? Answer 1, Answer 2
2. Feature Selection and Feature Extraction
- What do you mean by Curse of Dimensionality? How to deal with it?
- What is Dimension Reduction in Machine Learning? Why is it required? Answer
- What is the difference between Feature Selection and Feature Extraction?
- What are the various Dimensionality Reduction Techniques? Answer
4. Principal Component Analysis
- What is Principal Component Analysis (PCA)?
- How do we find Principal Components through Projections and Rotations?
- How will you find your first Principal Component (PC1) using SVD?
- What is Singular Vector or Eigenvector? What do you mean by Eigenvalue and Singular Value? How will you calculate it?
- What do you mean by Loading Score? How will you calculate it?
- "Principal Component is a linear combination of existing features." Illustrate this statement.
- How will you find your second Principal Component (PC2) once you have discovered your first Principal Component (PC1)?
- How will you calculate the variation for each Principal Component?
- What is Scree Plot? How is it useful?
- How many Principal Components can you draw for a given sample dataset?
- Why is PC1 more important than PC2 and so on?
- What are the advantages and disadvantages of PCA? Answer
5. What is SVD (Singular Value Decomposition)?
6. Linear Discriminant Analysis
- What is LDA (Linear Discriminant Analysis)?
- How does LDA create a new axis by maximizing the distance between means and minimizing the scatter? What is the formula?
- What are the similarities and differences between LDA and PCA (Principal Component Analysis)?
- What is Multi-Dimensional Scaling?
- What is the difference between "Metric" and "Non-metric" MDS?
- What is PCoA (Principal Coordinate Analysis)?
- Why should we not use Euclidean Distance in MDS to calculate the distance between variables?
- How is Log Fold Change used to calculate the distance between two variables in MDS?
- What are the similarities and differences between MDS and PCA (Principal Component Analysis)?
- How is it helpful in Dimensionality Reduction?
- What is t-SNE (t-Distributed Stochastic Neighbor Embedding)? Answer
- Define the terms: Normal Distribution, t-Distribution, Similarity Score, Perplexity
- Why is it called t-SNE instead of simple SNE? Why is t-Distribution used instead of normal distribution in lower dimension?
- Why should t-SNE not be used in larger datasets containing thousands of features? When should we use combination of both PCA and t-SNE?
- What are the advantages and disadvantages of t-SNE over PCA? Answer
Algorithms (27 Questions)
1. Types of ML Algorithms
- What are the various types of Machine Learning Algorithms? Answer
- Name various algorithms for Supervised Learning, Unsupervised Learning and Reinforcement Learning.
- What are the various Supervised Learning techniques?
- What is the difference between Classification and Regression algorithms?
- Name various Classification and Regression algorithms.
- What are the various Unsupervised Learning techniques?
- What is the difference between Clustering and Association algorithms?
- Name various Clustering and Association algorithms.
- How do we draw the line of linear regression using Least Square Method? What is the equation of line? How do we calculate slope and coefficient of a line using Least Square Method?
- Explain Gradient Descent. How does it optimize the Line of Linear Regression? Answer
- What are the various types of Linear Regression? What is the difference between Simple, Multiple and Polynomial Linear Regression?
- What are the various metrics used to check the accuracy of the Linear Regression? Answer
- What are the advantages and disadvantages of Linear Regression? Answer
- What is the equation of Logistic Regression? How will you derive this equation from Linear Regression (Equation of a Straight Line)?
- How do we calculate optimal Threshold value in Logistic Regression?
- What are the advantages and disadvantages of Logistic Regression? Answer
6. What is the difference between Linear Regression and Logistic Regression? Answer
7. KNN
- What is “K” in KNN algorithm? How to choose optimal value of K? Answer
- Why the odd value of “K” is preferable in KNN algorithm? Answer
- Why is KNN algorithm called Lazy Learner? Answer
- Why should we not use KNN algorithm for large datasets? Answer
- What are the advantages and disadvantages of KNN algorithm? Answer
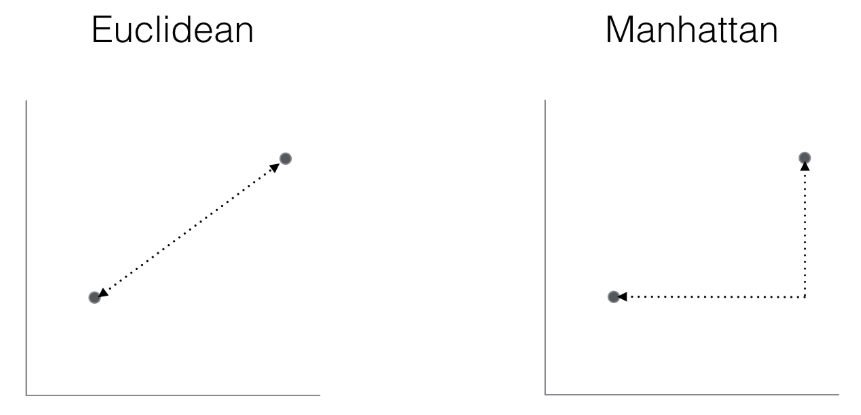
- What is the difference between Euclidean Distance and Manhattan Distance? What is the formula of Euclidean distance and Manhattan distance? Answer
- Define the terms: Support Vectors and Hyperplanes
- What are Kernel Functions and Tricks in SVM? What are the various types of Kernels in SVM? What is the difference between Linear, Polynomial, Gaussian and Sigmoid Kernels? How are these used for transformation of non-linear data into linear data?
- Can SVM be used to solve regression problems? What is SVR (Support Vector Regression)?
- What are the advantages and disadvantages of SVM? Answer
- What is the difference between Conditional Probability and Joint Probability?
- What is the formula of "Naive Bayes" theorem? How will you derive it?
- Why is the word “Naïve” used in the “Naïve Bayes” algorithm?
- What is the difference between Probability and Likelihood?
- How do we calculate Frequency and Likelihood tables for a given dataset in the “Naïve Bayes” algorithm?
- What are the various type of models used in "Naïve Bayes" algorithm? Explain the difference between Gaussian, Multinomial and Bernoulli models.
- What are the advantages and disadvantages of "Naive Bayes" algorithm? Answer
- What’s the difference between Generative and Discriminative models? What is the difference between Joint Probability Distribution and Conditional Probability Distribution? Name some Generative and Discriminative models.
- Why is Naive Bayes Algorithm considered as Generative Model although it appears that it calculates Conditional Probability Distribution?
11. Decision Tree
- Define the terms: GINI Index, Entropy and Information Gain. How will you calculate these terms from a given dataset to select the nodes of the tree?
- What is Pruning in a Decision Tree? Define the terms: Bottom-Up Pruning, Top-Down Pruning, Reduced Error Pruning and Cost Complexity Pruning.
- What are the advantages and disadvantages of a Decision Tree? Answer
- How is Decision Tree used to solve the regression problems?
- What is Random Forest? How does it reduce the over-fitting problem in decision trees? Answer
- What are the advantages and disadvantages of Random Forest algorithm? Answer
- How to choose optimal number of trees in a Random Forest? Answer
14. Bias and Variance
- What is the difference between Bias and Variance? What’s the trade-off between Bias and Variance?
- What is the general cause of Overfitting and Underfitting? What steps will you take to avoid Overfitting and Underfitting? Answer
15. Cross Validation
- What is Cross Validation? What is the difference between K-Fold Cross Validation and LOOCV (Leave One Out Cross Validation)?
- What are Hyperparameters? How does Cross Validation help in Hyperparameter Tuning? Answer
- What are the advantages and disadvantages of Cross Validation? Answer
16. Regularization
- What is Regularization?
- When should one use Regularization in Machine Learning?
- How is it helpful in reducing the overfitting problem? Can regularization lead to underfitting of the model?
- What is the difference between Lasso (L1 Regularization) and Ridge (L2 Regularization) Regression? Which one provides better results? Which one to use and when? Answer
- What is Elastic Net Regression?
17. Ensemble Learning
- What do you mean by Ensemble Learning?
- What are the various Ensemble Learning Methods?
- What is the difference between Bagging (Bootstrap Aggregating) and Boosting? Answer
- What are the various Bagging and Boosting Algorithms?
- Differentiate between Random Forest, AdaBoost, Gradient Boosting Machine (GBM) and XGBoost? Answer 1, Answer 2, Answer 3
- What do you know about AdaBoost Algorithm?
- What are Stumps? Why are the stumps called Weak Learners?
- How do we calculate order of stumps (which stump should be the first one and which should be the second and so on)?
- How do we calculate Error and Amount of Say of each stump? What is the mathematical formula?
20. GBM (Gradient Boosting Machine)
- What is GBM (Gradient Boosting Machine)?
- What is Gradient Descent? Why is it so named?
- How will you calculate the Step Size and Learning Rate in Gradient Descent?
- When to stop descending the gradient?
- What is Stochastic Gradient Descent?
22. XGBoost
- What is XGBoost Algorithm?
- How is XGBoost more efficient than GBM (Gradient Boosting Machine)? Answer
- What are the advantages of XGBoost Algorithm? Answer
24. K-Means Clustering
- What are the various types of Clustering? How will you differentiate between Hierarchial (Agglomerative and Devisive) and Partitional (K-Means, Fuzzy C-Means) Clustering?
- How do you decide the value of "K" in K-Mean Clustering Algorithm? What is the Elbow method? What is WSS (Within Sum of Squares)? How do we calculate WSS? How is Elbow method used to calculate value of "K" in K-Mean Clustering Algorithm?
- How do we find centroids and reposition them in a cluster? How many times we need to reposition the centroids? What do you mean by convergence of clusters?
26. Time Series Analysis
- What are various components of Time Series Analysis? What do you mean by Trend, Seasonality, Irregularity and Cyclicity?
- To perform Time Series Analysis, data should be stationary? Why? How will you know that your data is stationary? What are the various tests you will perform to check whether the data is stationary or not? How will you achieve the stationarity in the data?
- How will you use Rolling Statistics (Rolling Mean and Standard Deviation) method and ADCF (Augmented Dickey Fuller) test to measure stationarity in the data?
- What are the ways to achieve stationarity in the Time Series data?
- What is ARIMA model? How is it used to perform Time Series Analysis?
- When not to use Time Series Analysis?
- What do you mean by Sentiment Analysis? How to identify Positive, Negative and Neutral sentiments?
- What is Polarity and Subjectivity in Sentiment Analysis?
1. Name some metrics which we use to measure the accuracy of the classification and regression algorithms.
Hint:
Classification metrics: Confusion Matrix, Classification Report, Accuracy Score etc.
Regression metrics: MAE, MSE, RMSE Answer
2. What is Confusion Matrix? What do you mean by True Positive, True Negative, False Positive and False Negative in Confusion Matrix?
3. How do we manually calculate Accuracy Score from Confusion Matrix?
4. What is Sensitivity (True Positive Rate) and Specificity (True Negative Rate)? How will you calculate it from Confusion Matrix? What is its formula?
5. What is the difference between Precision and Recall? How will you calculate it from Confusion Matrix? What is its formula?
6. What do you mean by ROC (Receiver Operating Characteristic) curve and AUC (Area Under the ROC Curve)? How is this curve used to measure the performance of a classification model?
7. What do you understand by Type I vs Type II error ? What is the difference between them?
8. What is Classification Report? Describe its various attributes like Precision, Recall, F1 Score and Support.
9. What is the difference between F1 Score and Accuracy Score?
10. What do you mean by Loss Function? Name some commonly used Loss Functions. Define Mean Absolute Error, Mean Squared Error, Root Mean Squared Error, Sum of Absolute Error, Sum of Squared Error, R Square Method, Adjusted R Square Method. Answer
Python (16 Questions)
1. What are the commonly used libraries in Python for Machine Learning? Explain pandas, numpy, sklearn, matplotlib, seaborn and scipy libraries.
2. Which data structures in Python are commonly used in Machine Learning? Explain tuple, list and dictionary. Answer
3. What are mutable and immutable objects in Python?
4. What are the magic functions in IPython?
5. What is the purpose of writing "inline" with "%matplotlib" (%matplotlib inline)?
6. What are the basic steps to implement any Machine Learning algorithm in Python?
Implement KNN in Python
Implement SVC in Python
Implement Naive Bayes in Python
Implement Simple Linear Regression in Python
Implement Multiple Linear Regression in Python
Implement Decision Tree for Classification Problem in Python
Implement Decision Tree for Regression Problem in Python
Implement Random Forest for Classification Problem in Python
Implement Random Forest for Regression Problem in Python
Implement Adaboost in Python
Implement XGBoost For Classification Problem in Python
Implement XGBoost For Regression Problem in Python
7. What are the basic steps to implement any Machine Learning algorithm using Cross Validation (cross_val_score) in Python?
Implement KNN using Cross Validation in Python
Implement Naive Bayes using Cross Validation in Python
Implement XGBoost using Cross Validation in Python
8. Feature Scaling in Python
Implement Standardization in Python
Implement Normalization in Python
9. Encoding in Python
Implement LabelEncoder in Python
Implement OneHotEncoder in Python
Implement get_dummies in Python
10. Imputing in Python
Implement Imputer in Python
11. Binning in Python
Implement Binning in Python using Cut Function
12. Dimensionality Reduction in Python
Implement PCA in Python
13. What is the random_state (seed) parameter in train_test_split?
14. What are the various metrics present in sklearn library to measure the accuracy of an algorithm? Describe classification_report, confusion_matrix, accuracy_score, f1_score, r2_score, score, mean_absolute_error, mean_squared_error.
15. Pandas Library
Data Exploration using Pandas Library in Python
Creating Pandas DataFrame using CSV, Excel, Dictionary, List and Tuple
Boolean Indexing: How to filter Pandas Data Frame?
How to find missing values in each row and column using Apply function in Pandas library?
How to calculate Mean and Median of numeric variables using Pandas library?
Sorting datasets based on multiple columns using sort_values
How to view and change datatypes of variables or features in a dataset?
How to print Frequency Table for all categorical variables using value_counts() function?
Frequency Table: How to use pandas value_counts() function to impute missing values?
How to use Pandas Lambda Functions for Data Wrangling?
How to separate numeric and categorical variables in a dataset using Pandas and Numpy Libraries in Python?
16. Scipy Library
How to find mode of a variable using Scipy library to impute missing values?
Practical Implementations (5 Questions)
1. Write a pseudo code for a given algorithm.
2. What are the parameters on which we decide which algorithm to use for a given situation?
3. How will you design a Chess Game, Spam Filter, Recommendation Engine etc.?
4. How can you use Machine Learning Algorithms to increase revenue of a company?
5. How will you design a promotion campaign for a business using Machine Learning?